
Data modernization has become an urgent competitive necessity for businesses to stay ahead of the curve – anticipate market changes earlier, understand customer needs more closely, and take and implement winning decisions faster than the competition.
That said, technology leaders need to assess the pros and cons of a modernization exercise. Businesses must study the various avenues for modernization and choose the one that gives them the best cost-benefit balance. As with any change management initiative, it is disruptive and entails focused deployment of resources.
In this article, I will discuss three frameworks/platforms that, we at ITC Infotech have helped our clients use to effectively leverage data for business success.
The Data Warehouse
The Data Warehouse was probably the first enterprise-level platform to use data for business decision support. It came into its own in the Nineties and at the turn of the new Millennium. As its name implies it organized data in structured and labelled fields that could be easily accessed, and it worked excellently.
Data-driven business intelligence, as a concept, gained massive leverage thanks to the Data Warehouse. However, like its counterpart in the real world, the Data Warehouse’s key drawback is poor scalability. It works on pre-built schema and can take in only structured data. As a result, the data is siloed and not all data is captured.
As the three Vs of data – volume, variety, and velocity – grow, as in today’s age of Big Data, the Data Warehouse becomes unwieldy and inefficient. And data’s fourth V, veracity, suffers in consequence.
This is not to say that the Data Warehouse has outlived its utility. It still works efficiently for businesses that deal with a smaller volume and variety of data and provides excellent decision support intelligence at a relatively lower investment.
The Data Lake
The Data Warehouse’s inherent problems gave rise to the Data Lake, a platform with no hierarchical structure that is more attuned to the needs of Big Data.
A data lake is like a reservoir into which raw data can be poured and stored until needed. It has a flat architecture and takes in data in their native formats – emails, documents, images, audio, video, semi-structured data, such as CSV, logs, and XML, as well as structured data from relational databases.
The extract-transform-load process happens within the Lake itself and data is presented as reports, dashboards, and such, to facilitate better visualization and more accurate analytics, as well as to enable machine learning.
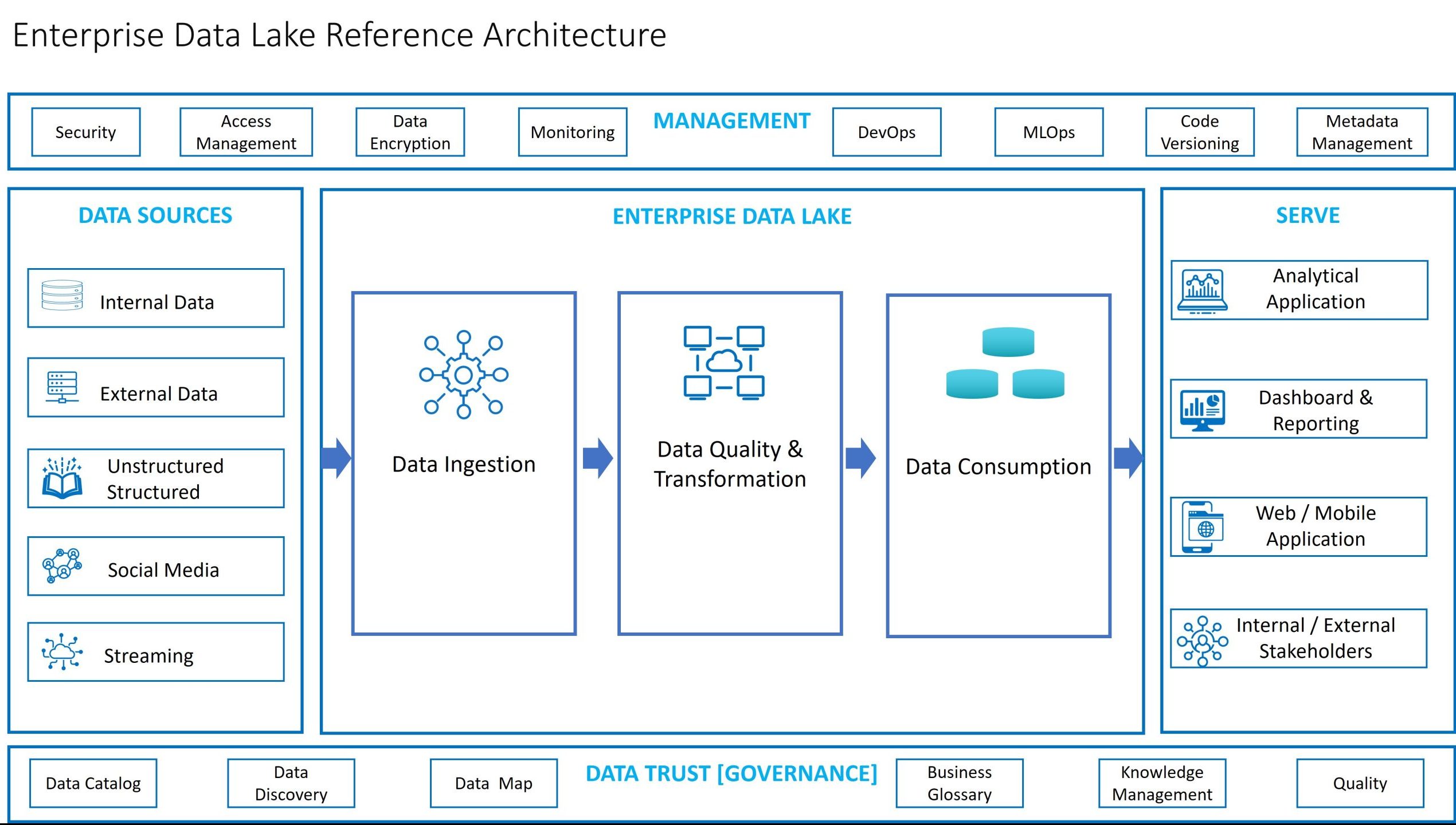
The Data Lake is thus capable of managing the high Volume, high Variety, and high Velocity of Big Data.
However, the Data Lake also has its drawbacks.
Once data is put into the Lake, it becomes monolithic. This limits the knowledge that data analysts can gain from it and increases the risk of valuable information going unnoticed.
Its centralized control structure stretches the IT team thin. Projects get delayed, forcing teams to resort to poorly integrated ‘quick-fix’ solutions that eventually compound problems.
Consequently, it often ends up as a huge unmanageable data dump yard. Drawing any useful sense out of the Data Lake becomes a complex, expensive, and resource-intensive task.
It is in response to these problems that the concept of a Data Mesh came into being.
The Data Mesh
Unlike the Data Lake, the Data Mesh is a composite, integrated ecosystem, and not a monolith. It is composed of decentralized subsystems or domains, each managed by a dedicated team. In a sense, you can say that the Data Mesh as a whole is greater than the sum of its parts.
It thus offers several advantages over the Data Lake.
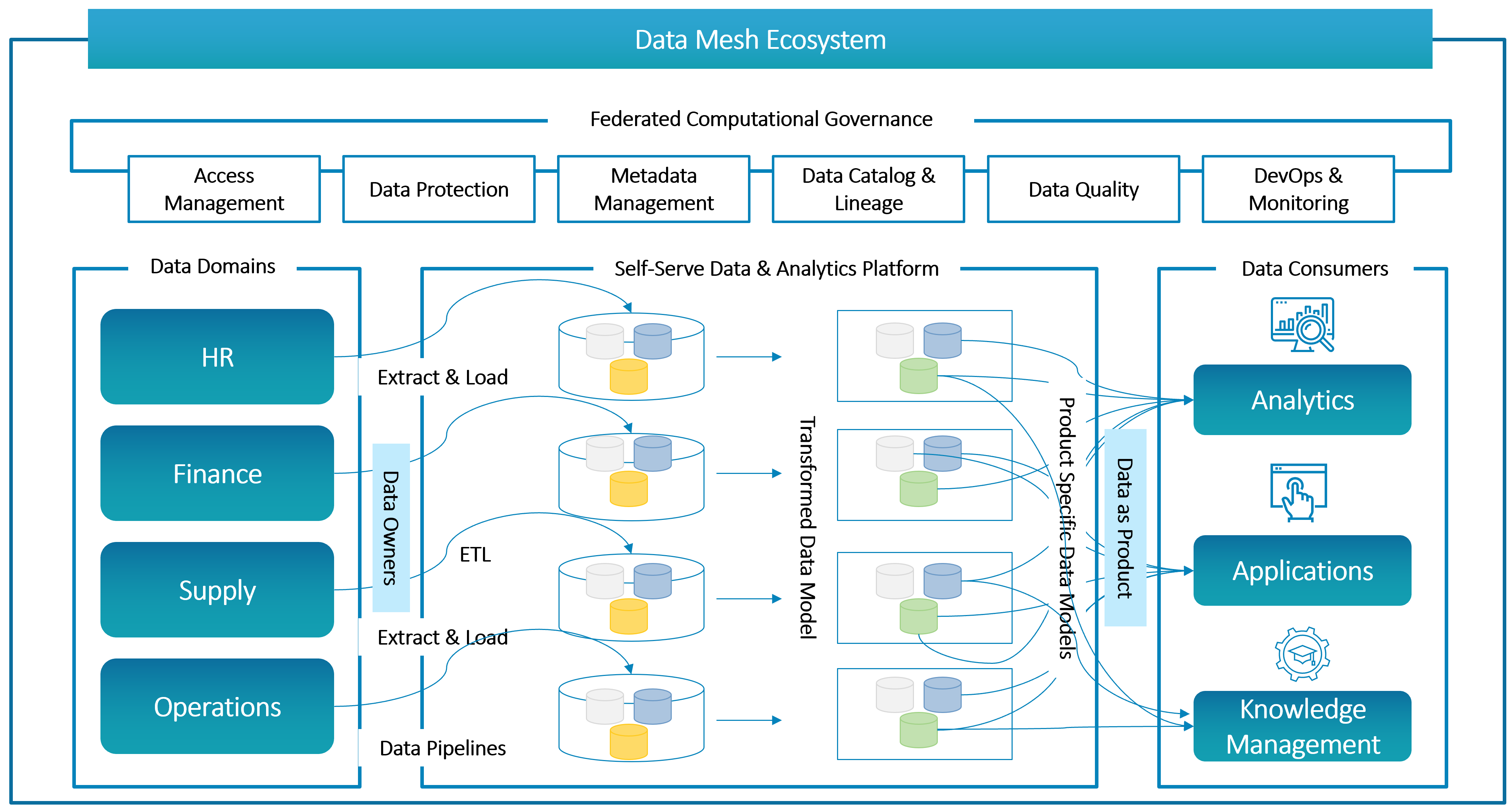
It makes domain experts owners of their data. Thus, there is no danger of valuable nuggets of information being lost or ignored.
It treats data as a product and enables a smooth and secure flow of data from producers to users, whether outside or within a Data Lake. In that sense, a Data Mesh may include Data Lakes.
It encourages cross-functional teams and empowers them to operate independently, with little or no support from a central IT function. Collaboration is more efficient, the pace of development accelerates, and projects go live much sooner.
Its decentralized approach gives you the flexibility to choose vendors and technologies that work best for you, without getting locked onto one platform.
A Data Mesh can be deployed for a broad range of needs and for diverse use cases:
- Migrating applications to the cloud
- Modernizing data lakes to make data more easily accessible
- Integrating apps, IoT, and analytics in real-time
- Streaming data pipelines within or from data lakes
- Data-in-motion analytics
So which modernization solution is best for your organization?
Talk to us at ITC Infotech. We’ll undertake an assessment of your existing digital landscape, identify modernization areas, build a strategic roadmap, and define the enterprise architecture you need.
We are part of the Data & Analytics transformation journey over last 15 years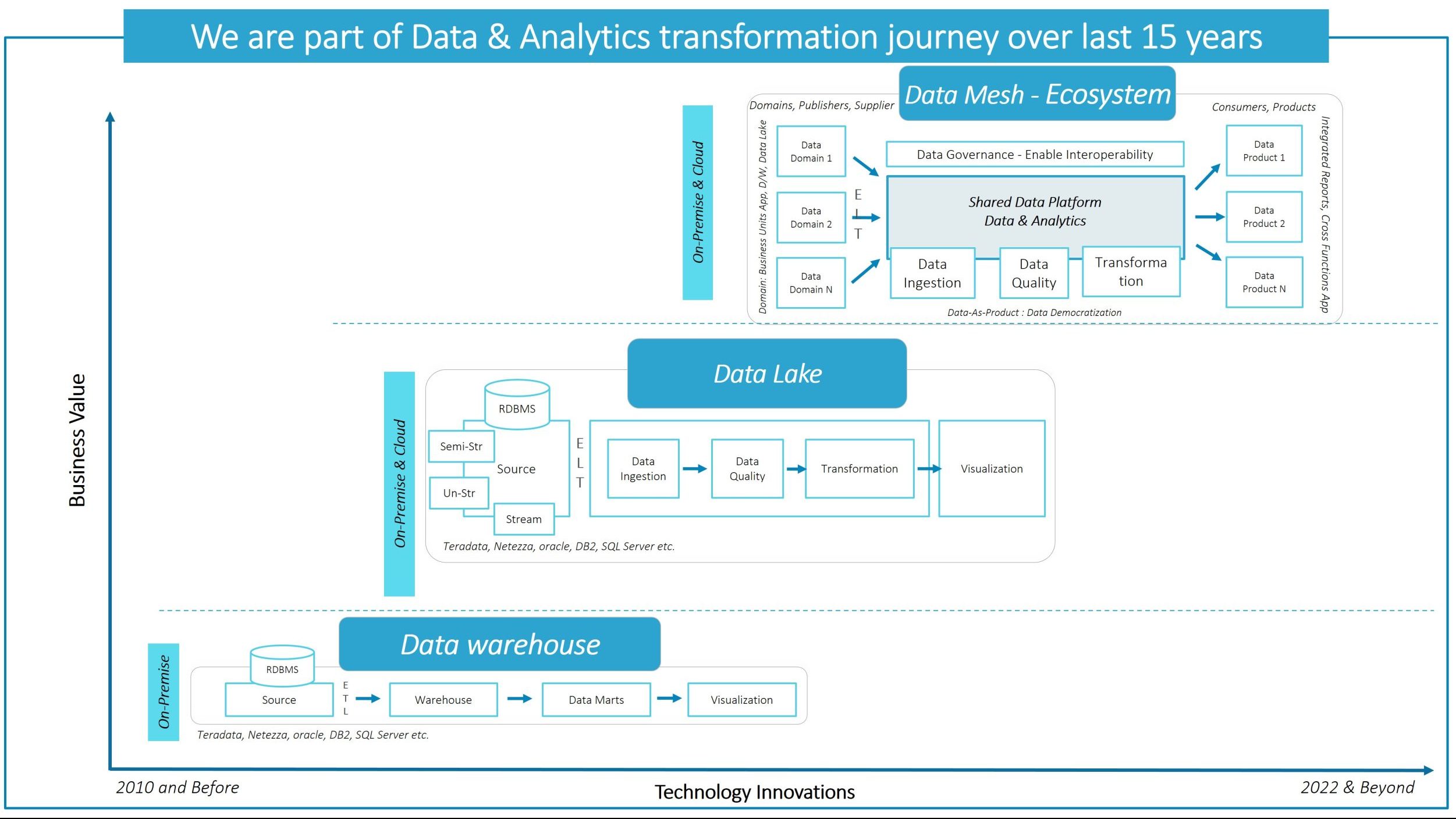
Build a Scalable, Flexible & Secure Data Ecosystem | Enable Insights-powered Decisions | Be Future Ready to leverage AI/ML | Gain Business Intelligence Faster and Cheaper | Enable Rapid Value-led Experimentation | Drive Data-as-a-Service
Click here for Part of 2 blog: Data Modernization – What is the best route for your transformation journey? (Part 2)
Author:
Bhagaban Khatai
Data Transformation Leader
Reference:
Zhamak Dehghani
Data Mesh Founder
Recent Posts
 SAP S/4HANA migration: Why waiting is becoming the more expensive investment decision
SAP S/4HANA migration: Why waiting is becoming the more expensive investment decision From Digital Thread to Agentic Operations: What Manufacturing Leaders Need Next
From Digital Thread to Agentic Operations: What Manufacturing Leaders Need Next PPWR Compliance Will Fail Without SKU-Level Packaging Data. Is your Company ready?
PPWR Compliance Will Fail Without SKU-Level Packaging Data. Is your Company ready?- Why Disconnected Packaging Data Could Become the Biggest PPWR Risk for CPG Companies
 From Spending to Scaling: Architecting AI for Sustainable Business Value
From Spending to Scaling: Architecting AI for Sustainable Business Value




